Feature Pyramid Networks for Object Detection
Статье уже 8 лет, т.е. по нынешним быстробегущим временам написана была давным давно. Однако, техника, описанная в статье применяется в разных местах до сих пор. Собственно, чего бы ей не применяться, если по сути это тот же классический подход, который использовался при решении задачи детектирования объектов во времена, когда сверточные сети еще не завоевали мир, а в ходу были вручную придуманные признаки.
Давным давно, методы детектирование объектов на изображении выглядили достаточно однообразно. Раазница была только в алгоритме получения признаков по входной картинке, и таких алгоритмов было придумано достаточно много, начиная со статьи Виола-Джонcа и вплоть до ACF, ICF и пр. В остальном схема был стандартной. Первым делом тренируем классификатор объект/не объект для “маленькой” картинки, признаки для которой вычисляются при помощи придуманного алгоритма. Имея такой классификатор, и входное изображение на котором мы хотим детектировать объекты, Строим по входному изображению пирамиду, т.е. масштабируем исходное изображение с определенным шагом (обычно задается число октав и кол-во промежуточных картинок в октаве, сама октава - это уменьшение картинки в два раза по обеим осям) и на каждой картинке из пирамиды запускаем “скользящее окно” (т.е. окно, размером равное размеру входа классификатора, которое с определенным шагом сдвигается по картинке), для каждого окна вычисляем признаки и проверяем классификатором есть ли объект в окне объект.
Завершающим этапом обычно используется NMS потому что по одному реальному объекту мы обычно находим несколько положительных откликов классификатора (в окнах близких на одном уровне пирамиды и возможно даже на разных уровнях).

Проблемы в классическом подходе ровно две: придумать хороший алгоритм вычисления признаков и научиться быстро эти признаки вычислять, потому что окошек на картинке обычно надо проверить ну очень много.
Чтобы вычислять быстро предлагалось, например, вычислять признаки только на границах октав (т.е. для картинок с масштабом степенью двойки), а промежуточные уровни внутри октавы интерполировать (отмечу, именно признаки интерполировать, не изображения).
Но классические алгоритмы получения признаков перестали быть актуальными им на смену пришли сверточные нейронные сети, придумывать алгоритмы вычисления признаков стало не нужно, а за скорость стали отвечать видеокарточки (которые правда не всегда справляются с сильно возросшими запросами).
Варианты пирамиды
Когда мы строим детектор в виде нейронной сети обычно выделяется базовая часть (т.н. backbone или feature extractor), которая по изображению генерирует тензор признаков, и несколько дополнительных сетей, которые получают на вход признаки от backbone и решают уже конкретные задачи: классификации (например, задачу бинарной классификации: присутствует ли объект в данном месте) или регрессии (уточнение координат объекта). Мы уже разбирали два класса детекторов на базе сверточных сетей. Во-первых, Fast-RCNN, Faster-RCNN - здесь признаки берутся с последнего слоя сверточной сети, при этом геометрические размеры тензора обычно в 32 раза меньше геометрических размеров исходной картинки.

Эти признаки, полученные с последнего слоя сверточной сети, используются в RPN - для определения наличия/отсутствия объекта и уточнения его позиции. Напомню. RPN - это просто небольшая сверточная сеть (вначале свертка с ядром 3x3 потом свертки с ядрами 1x1 - фактически полносвязные слои, или, что тоже самое линейные классификатор и регрессоры), которая отдает бинарный ответ о наличии объекта и уточнения для его позиции и размера. При этом в Faster RCNN используется понятие anchor, т.е. для каждой точки $(x_f, y_f)$ тензора признаков мы проверяем несколько вариантов прямоугольников объектов на изображении с центром в точке соответствующей $(x_f, y_f)$. Anchor-ы варьируют масштаб (т.е. размер прямоугольника на исходной кратинке) и пропорции объекта. В Faster RCNN, получив прямоугольники претендентов при помощи RPN, те же признаки, подаются через процедуру ROIPool на вход еще одного многоклассового классификатора и регрессора для окончательного вердикта.
Проблема здесь в том, что на последнем слое признаки имеют очень грубую (масштаб 1/32) геометрическую размерность.
Другой класс детекторов, который мы тоже рассматривали YOLO-SSD. В SSD признаки брались не только с последнего слоя backbone сети, но и с промежуточных. Надо отметить, что свёрточные сети, используемые в качестве backbone, обычно разбиваются на уровни, похожие на уровни нашей пирамиды: несколько свёрточных слоёв (разностных свёрточных слоёв для ResNet, например), которые не меняют геометрические размеры тензора, а затем слой со stride = 2, который масштабирует тензор в два раза по геометрическим осям.
С одной стороны на нижних уровнях пирамиды признаков, формируемой свёрточной сетью, мы имеем большую чувствительность по точности позиции и размеров и просто можем хоть как-то улавливать объекты малых размеров. С другой стороны чем выше уровень пирамиды тем более сильные признаки мы можем получить (несколько угрубляя можно сказать, что на первых уровнях признаки отвечают за простые геометрии, а на верхних уровнях за части объектов и сами объекты).
Следующий вариант (от плюс-минус тех же авторов, что и данная статья, см. Learning to Refine Object Segments ) - это после получения пирамиды признаков, пройти обратным путем с верхушки пирамиды вниз, масштабируя слой переходя с уровня на уровень и подклеивая всё более точные (в геометрическом плане), но всё более слабые (с точки зрения качества признаков) слои из пирамиды. Таким образом, в результате получим один тензор признаков, который вобрал знания от сильных признаков с верхушки пирамиды, при этом имеет геометрические размеры такие же как исходное изображение.

Полученный таким образом слой признаков можно использовать, например, в Faster RCNN модели.
Feature Pyramid Networks
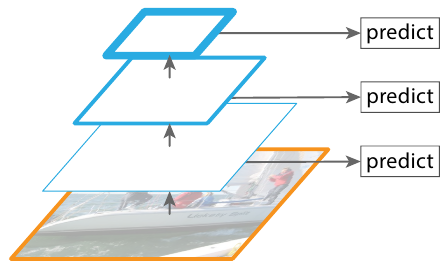
Наконец, переходим подходу, который описан в статье. Авторы предлагают модифицировать последний вариант из предыдущего пункта. Мы проходим сверху вниз по пирамиде, но при этом не собираем один слой признаков высокого разрешения, а запускаем алгоритм детектирования на каждом из уровней пирамиды. Фактически это в каком-то смысле аналогично классическому подходу со скользящим окном.

Заметим, что поскольку на каждом из уровней пирамиды мы применяем один и тот же классификатор/регрессор (например, для RPN сети), то тензоры на всех уровнях должны иметь одинаковое число каналов (в статье конкретно фиксируется 256 каналов).
Получение уровней пирамиды при проходе сверху вниз выглядит следующим образом. Для последнего слоя backbone сети мы просто применяем свёртку с ядром 1x1, получая набор признаков для самого верхнего уровня пирамиды. Дальше на каждом шаге: а) берем признаки с предыдущего уровня, масштабируем их в два раза по обеим осям, б) к признакам текущего уровня пирамиды применяем свёртку с ядром 1х1 (чтобы иметь фиксированное число каналов на всех уровнях), складываем тензоры а) и б) и дополнительно проходим по сумме сверткой 3x3 (авторы пишут, что это позволяет уменьшить эффекты от масштабирования).

Теперь можно использовать, полученные слои признаков в Faster RCNN сети. Если раньше для каждой точки слоя признаков (это был один слой - последний слой backbone сети) заводили несколько anchor с разными масштабами и соотношением сторон, то теперь масштаб задаётся тем слоем признаков на котором мы рассматриваем anchor (тем слоем который мы подаём в RPN), при этом для каждой точки берется несколько anchor-ов отличающихся соотношением сторон.
Еще одна часть Fast RCNN отвечает за непосредственно мультиклассовую классификацию и уточнение bbox-а претендента, который выдала RPN. Для этого используется ROI Pooling техника, согласно которой ROI на слое признаков, соответствующий bbox-у претендента на исходном изображении переводится в стандартный размер (для классической статьи про Fast RCNN это 7x7), который затем превращается в вектор из трехмерного тензора и подаётся на полносвязные слои (= линейные классификаторы). В случае FPN мы можем выбрать слой признаков наиболее подходящий для претендента соответствующего размера. Авторы предлагают следующую формулу:
\[k = \left \lfloor k_0 + log_2 (\sqrt{wh} / 224) \right \rfloor\]здесь $w,\,h$ - размеры претендента в системе координат изображения. $k_0$ - индекс топового слоя пирамиды (в классической Fast RCNN сети, признаки брались с самого верхнего слоя). Формула нам выдает, что если объект меньше по размеру чем 224, то мы берем один средних слоёв пирамиды (не слоёв backbone сети, а тех которые мы получили проходя сверху вниз и строя FPN), чем объект меньше тем ниже по пирамиде мы опускаемся. Дальше мы просто делаем ROI Pooling на этом слое и применяем полносвязные слои для классификации и т.п.
Важно отметить, что слои (коэффициенты) не зависят от того с какого слоя мы берем признаки.
Процесс тренировки нового варианта Faster RCNN с использованием FPN - ничем особенно не отличается от тренировки старого.
FPN, судя по экспериментам авторов статьи, даёт существенный прирост качества, особенно на небольших объектах.