Unsupervised Visual Representation Learning by Context Prediction
В статье представлен способ претренировки свёрточной нейронной сети, на неразмеченном датасете из изображений. Основная задача авторов, получить такие начальные веса свёрточной сети, которые позволят в дальнейшем натренировать уже конкретную сеть для классификации или детектирования лучше, чем если начинать просто со случайных весов.
Итак в прошлый раз мы разобрали статью про раскраску изображений и в ней тоже краем задели претренировку свёрточной сети на неразмеченном датасете. Но там это был в некотором роде побочный эффект, здесь же авторы именно что хотят получить методику тренировки, которая будет выдавать хорошие признаки, обучаясь без учителя.
Чтобы такую сеть претренировать, нужна какая-то задача, которая бы позволяла использовать просто датасет неразмеченных изображений и авторы статьи предлагают следующее (ссылаясь на предобучение сетей для задач связанных с текстами): возьмем изображение, выкусим из него два квадратных патча, и заставим сетку предсказывать их взаимное расположение. Чтобы это сделать сеть будет вынуждена научиться “понимать” картинки, а значит натренируется выделять из картинок хорошие признаки.
На самом деле задача формулируется даже несколько проще, мы выбираем центральный патч, а для второго патча надо предсказать один из восьми классов, которыми ограничивается его возможное положение:
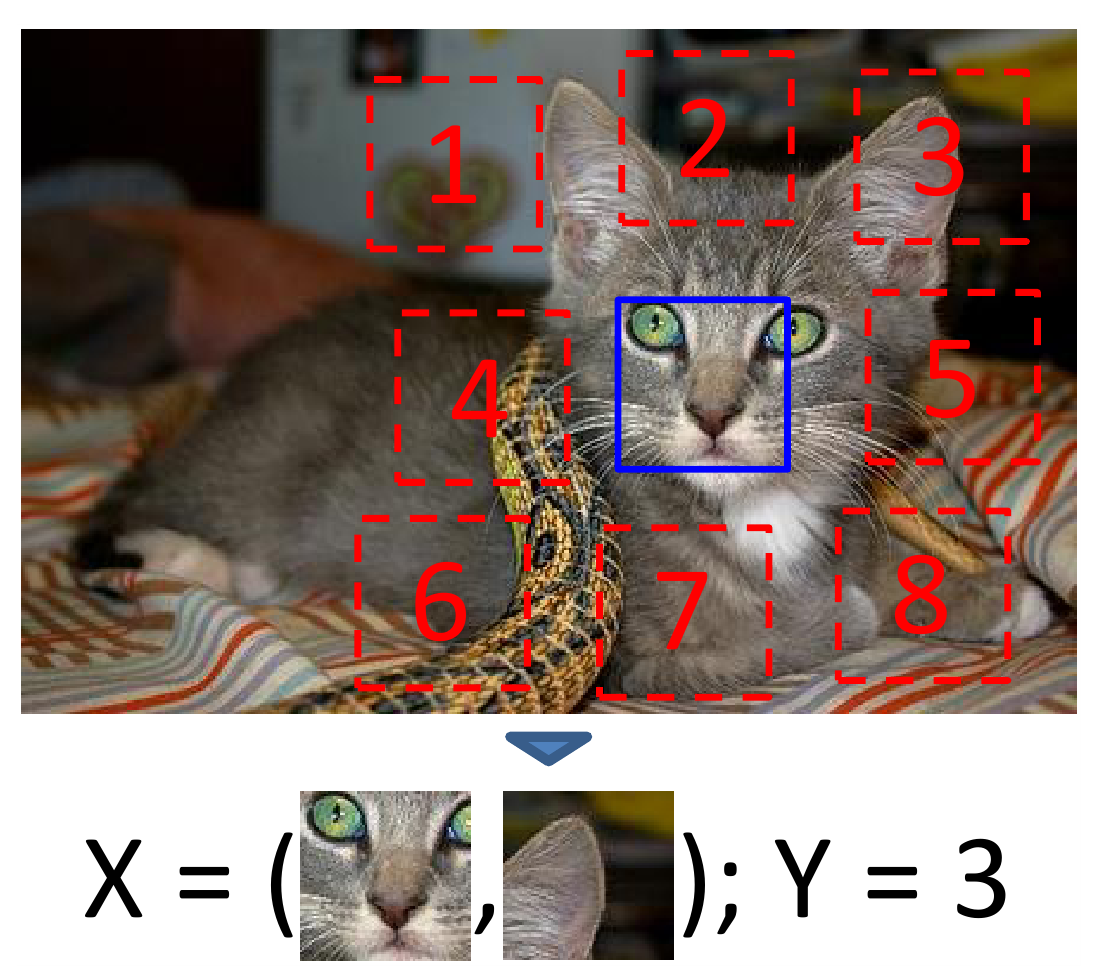
Надо отметить, что авторы подошли к делу со всей серьезностью, и постарались максимально усложнить сети задачу, чтобы в результате натренировать действительно хорошие, не тривиальные признаки.
Во-первых, они вырезают патчи не вплотную, а делают между ними пробел в 48 пикселей (сами патчи размера 96 на 96 пикселей), чтобы сеть не могла натренироваться на оценку только краёв патчей, и не пыталась использовать особенности текстур на краях для определения взаимного расположения патчей.
Во-вторых, авторы предположили, что просто разнести патчи на фиксированное расстояние недостаточно, потому что сеть может начать цепляться за прямые линии проходящие через несколько патчей, и, используя направления таких линий, решать задачу, что нас совершенно не устраивает, нам надо, чтобы сеть научилась выделять именно высокоуровневые признаки. Поэтому авторы добавляют “шевеление”, сдвигая координаты патчей случайным образом в пределах 7 пикселей по горизонтали и вертикали.
Наконец, авторы замечают, что сеть может зацепиться за хроматическую абберацию, и таким образом снова вместо выделения существенных семантических свойств натренироваться локализовывать патчи внутри изображения оценивая сдвиг между зеленым и фиолетовым (красным плюс синим) каналами, а затем основываясь на этой оценке выделять относительные позиции. Авторы предлагают два способа борьбы: первый - сдвигать зеленый и фиолетовый каналы, убирая влияние абберации, второй - заменить два случайно выбранных канала из трех на гауссов шум.
Итак определившись с алгоритмом формирования двух патчей, переходим к модели сети:
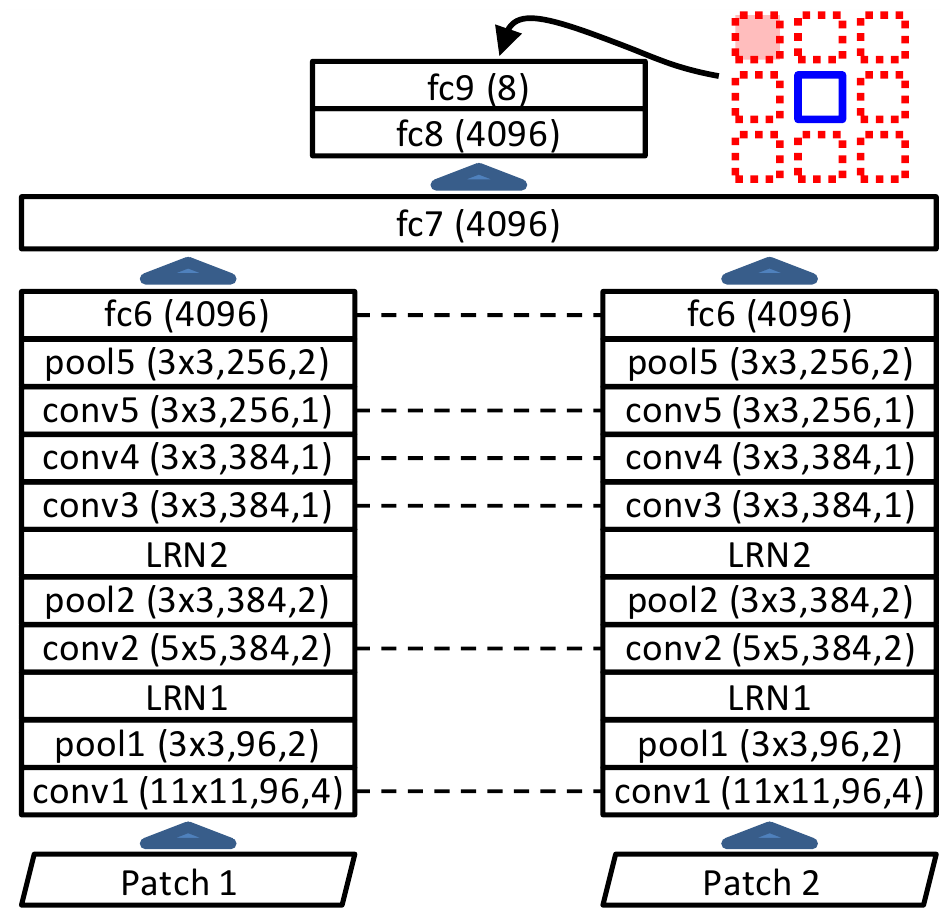
Здесь всё достаточно просто, оба патча прогоняют через одинаковый набор свёрточных и пулинг слоёв с одними и теми же весами. На выходе слоя fc6 для каждого патча получается вектор признаков длины 4096. Эти два вектора подаются в полносвязную сеть (fc8 и fc9) после которой и получаем ответ.
После того как сеть натренировалась, авторы решили оценить результаты.
Первое, что они сделали, попробовали взять большой набор патчей подсчитать для них вектора признаков (выход слоя fc6) и кластеризовать эти патчи на основе близости получившихся векторов. Точнее, они брали какой-то патч в качестве запроса и собирали $N$ ближайших к нему в пространстве признаков:

Для сравнения авторы так же взяли AlexNet, натренированную для классификации на ImageNet датасете и проделали тот же эксперимент с признаками, которые сгенерировала AlexNet. Еще они взяли признаки, которые выдавала их сеть до тренировки (т.е. в слоях выставлены просто случайные веса).
Выглядит так, что сеть, которая тренировалась в unsupervised варианте и AlexNet, которая тренировалась на классификационной задаче, показывают одинаково хорошие результаты (если судить по картинкам, пока тут никакой объективной количественно оценки нет). И местами даже сеть из разбираемой статьи в каком-то смысле лучше, например, она собрала не просто колеса, но колеса, расположенные на изображении так же как на патче-запросе.
Следующий тест - попробовать инициализировать весами из этой сети R-CNN модель для детектирования (вот да просто R-CNN, не Fast и не Faster разбираем статью 2015 года). Качество детектора вырастает на 6% относительно варианта, когда начальное состояние сети задаётся случайным образом.
Завершая. В статье описан интересный способ претренировывать сетку на неразмеченных данных, получая feature extractor для различных задач.